Depuis plusieurs mois, j’expérimente les assistants IA dans mes projets, et après avoir beaucoup travaillé avec Claude Code et constaté à quel point ces outils permettent de produire des applications à une vitesse impressionnante, notamment parce qu’ils m’aident à dépasser mes limites sur la partie IHM en tant que développeur backend, j’ai voulu tester GitHub Copilot avec le modèle Opus 4.5 afin de voir ce qu’il apportait concrètement dans mes développements. J’étais plus que sceptique. Quand quelque chose fonctionne très bien, on n’a pas forcément envie d’en changer. Et pourtant.
Pourquoi tester GitHub Copilot ?
La principale raison est simple : l’intégration IDE. J’utilise IntelliJ IDEA depuis des années. C’est mon environnement naturel de développement. Pouvoir utiliser un agent IA directement dans l’IDE, au plus proche du code, est un vrai confort. Oui, on peut connecter Claude Code à son IDE. Mais l’intégration reste moins fluide, moins native. On sent que ce n’est pas pensé au cœur de l’expérience développeur. Avec GitHub Copilot, l’expérience est intégrée dans l’éditeur et permet de naviguer dans les fichiers, générer du code, assister le refactoring et même créer des Pull Requests sans sortir de l’environnement.
Les “Agents” et les “Skills”
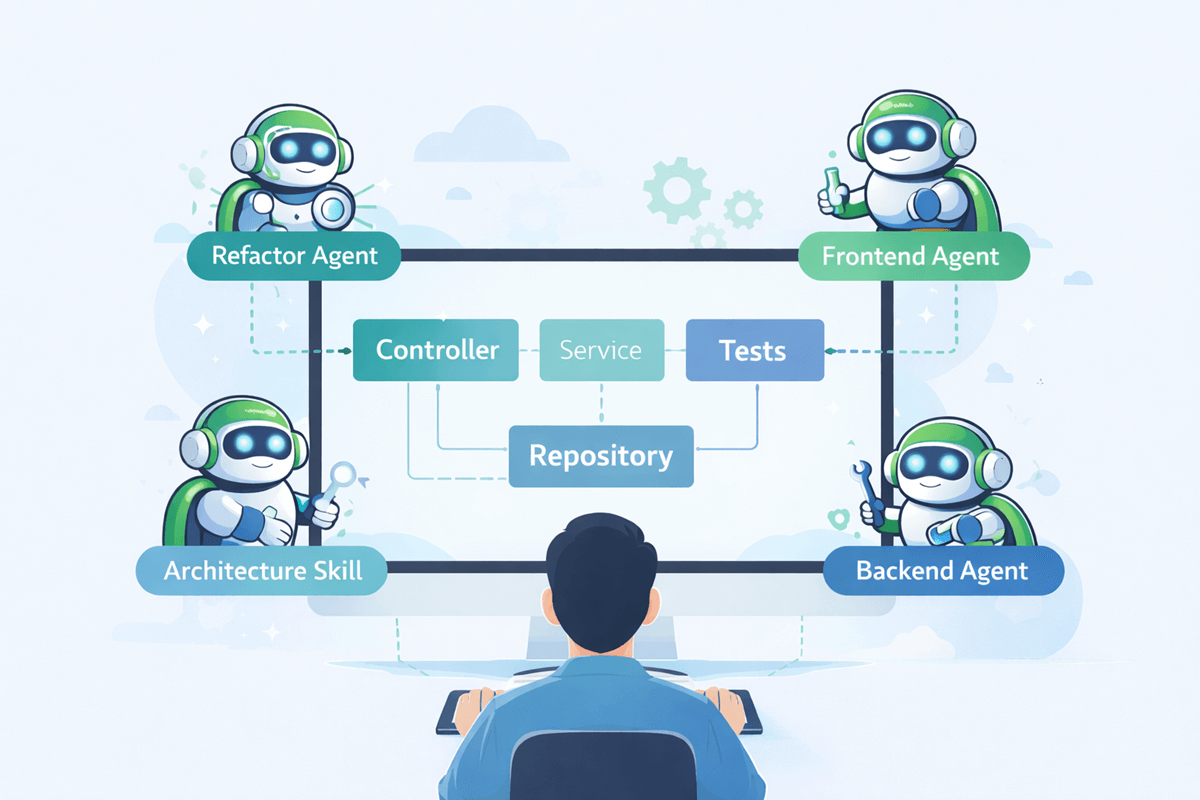
Même si cette approche existe aussi avec Claude Code, j’ai trouvé l’écosystème Copilot plus simple à prendre en main, mieux structuré et surtout accompagné de beaucoup plus d’exemples concrets prêts à l’emploi. En explorant l’écosystème Copilot, je suis tombé sur le dépôt awesome-copilot, qui propose une liste impressionnante d’agents et de skills prêts à l’emploi.
Concrètement, j’ai par exemple utilisé un agent de développement backend Spring qui sépare proprement les services, DTO et contrôleurs. J’ai aussi utilisé un skill de génération de tests pour créer une base de tests unitaires cohérente avec la structure Maven du projet. Dans les deux cas, l’agent ne s’est pas contenté d’ajouter du code : il a respecté l’architecture existante et les conventions définies dans le template, ce qui rend le résultat directement exploitable.
Création d’un template projet
Pour tester sérieusement, je ne voulais pas partir d’un simple projet vide. J’ai donc commencé par créer un template de projet adapté à mes technologies préférées : Java, Maven, Spring Boot et React via Vite. L’objectif était de poser un cadre clair dès le départ, avec une séparation propre entre backend et frontend, une configuration Maven standardisée et un environnement React immédiatement exploitable.
Cette base structurée permettait de laisser l’agent travailler efficacement sans ambiguïté sur l’architecture. Sur ce point, Copilot a été très pertinent : la génération est cohérente, les dossiers sont organisés logiquement et les conventions respectées. On sent que le modèle comprend l’architecture globale du projet, et pas seulement les lignes de code qu’il produit.
Le template est disponible ici :
https://github.com/sliard/JavaViteTemplate
Il repose sur une séparation claire entre un backend Spring Boot exposant une API REST et un frontend React (Vite) isolé, avec une configuration Maven standardisée et prête pour l’industrialisation. J’y ai également intégré une structure pensée pour les agents : dossiers explicites, README orienté contexte, scripts reproductibles et conventions strictes pour éviter toute ambiguïté lors de la génération.
Un point important concerne la formalisation des messages de commit. J’ai défini une convention claire, de type Conventional Commits, pour forcer l’agent à produire des messages structurés, explicites et exploitables dans un pipeline CI/CD. En cadrant le format attendu dès le départ, on améliore fortement la qualité des Pull Requests générées : description synthétique, contexte technique, liste des changements et impact potentiel. Petit plus lié à l’intégration IDE, la génération des messages de commit respectait cette règle à la lettre.
Projet test
Pour aller plus loin, j’ai utilisé ce template pour créer un projet test disponible ici :
https://github.com/sliard/TestChessCopilot
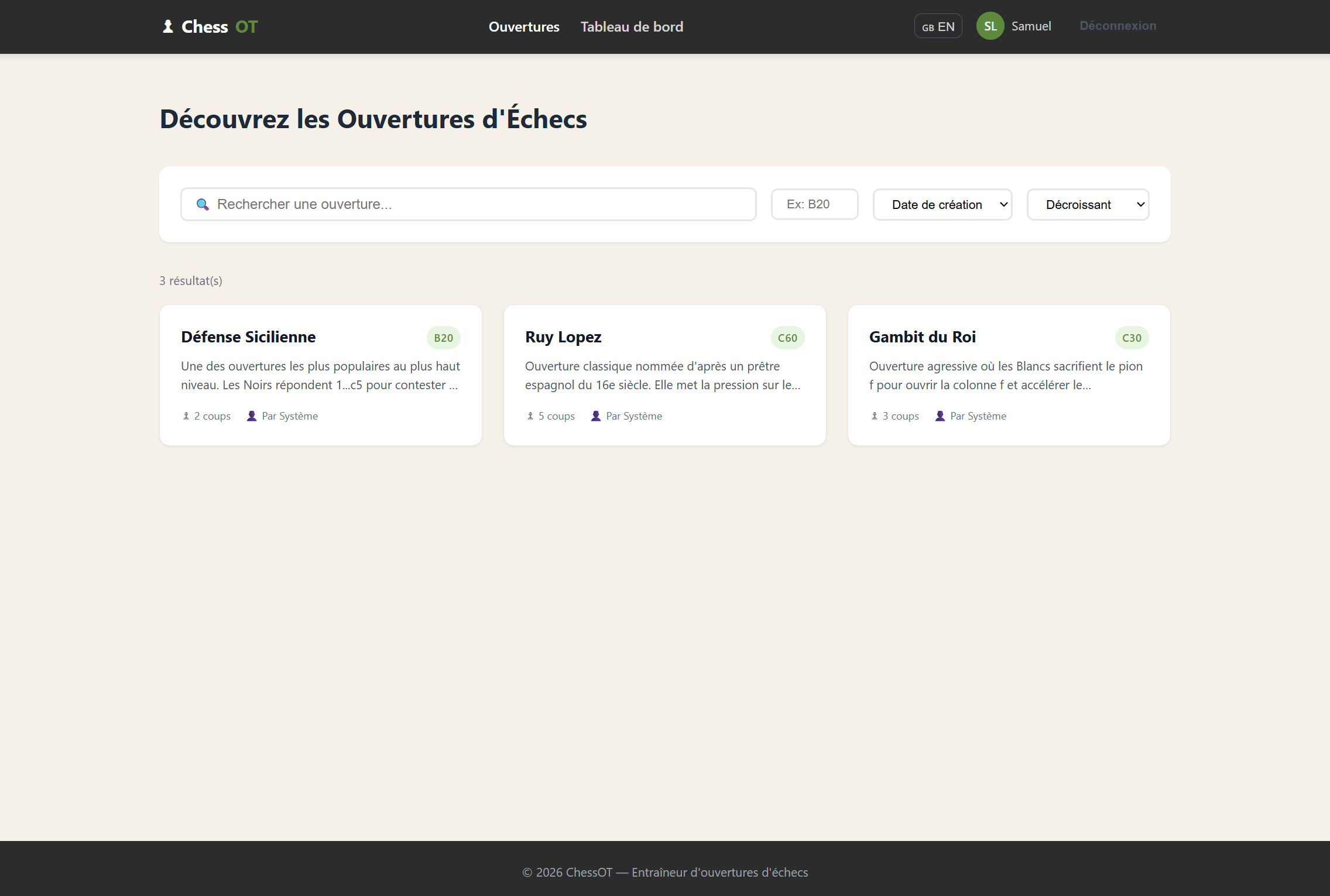
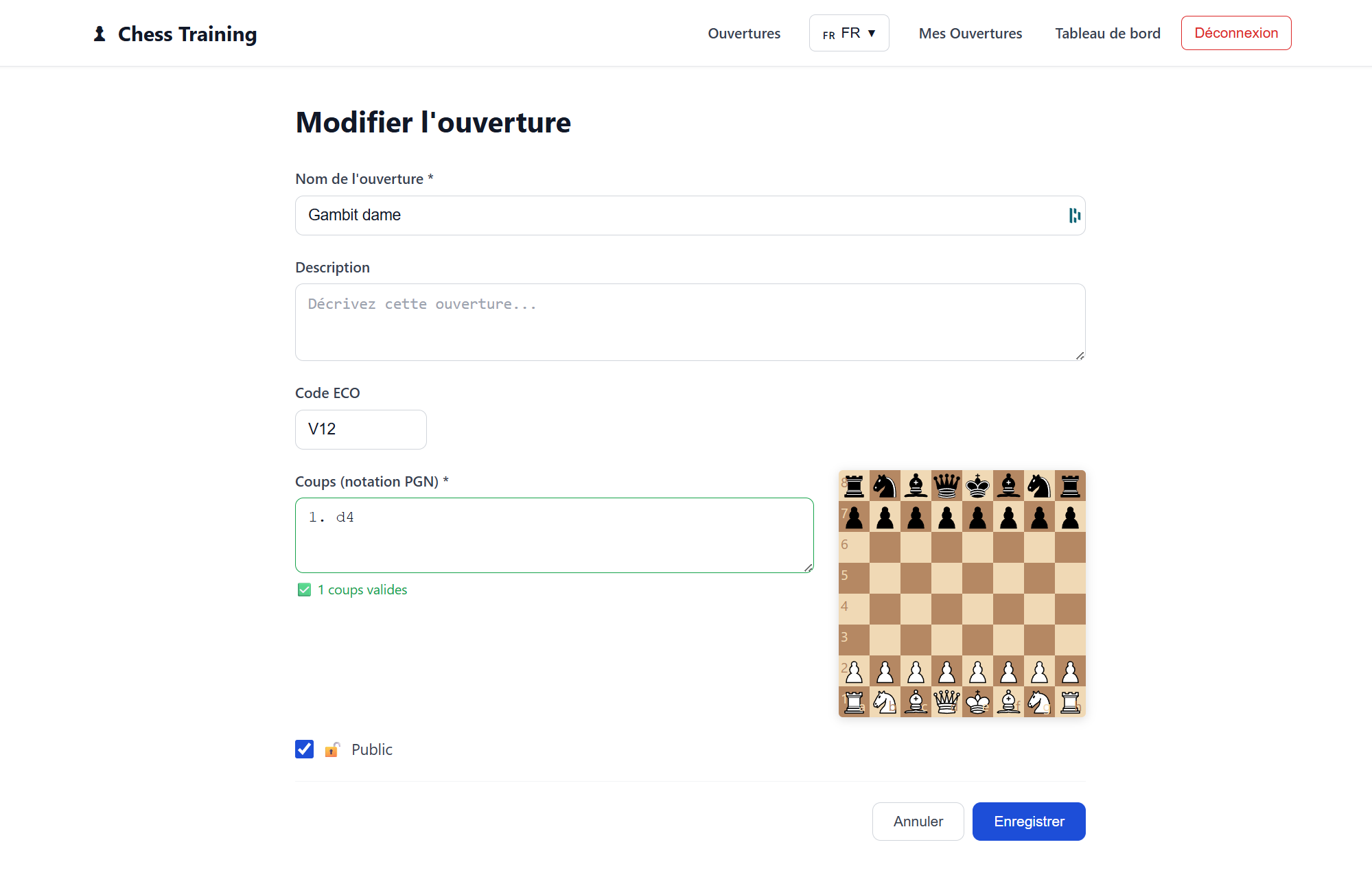
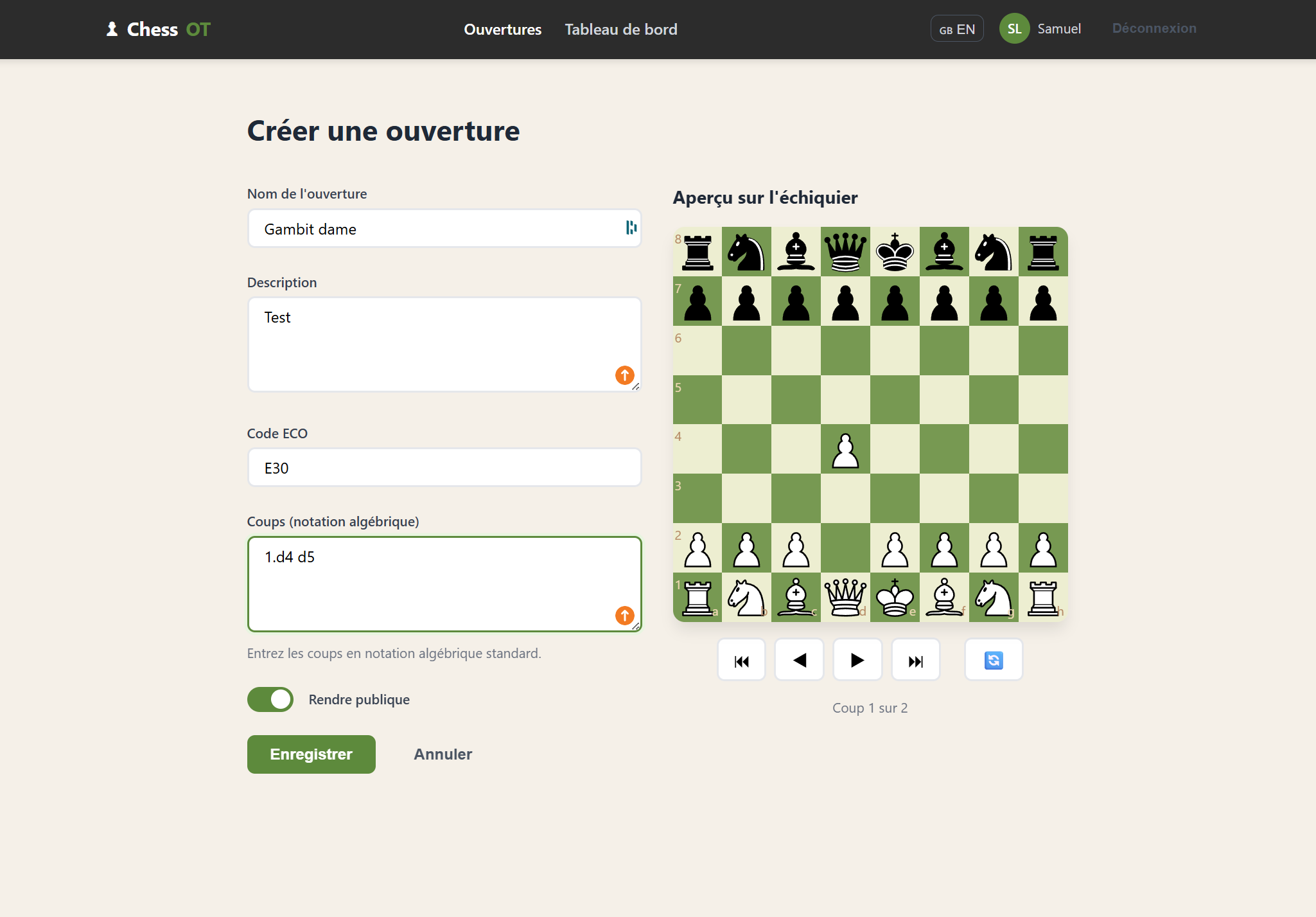
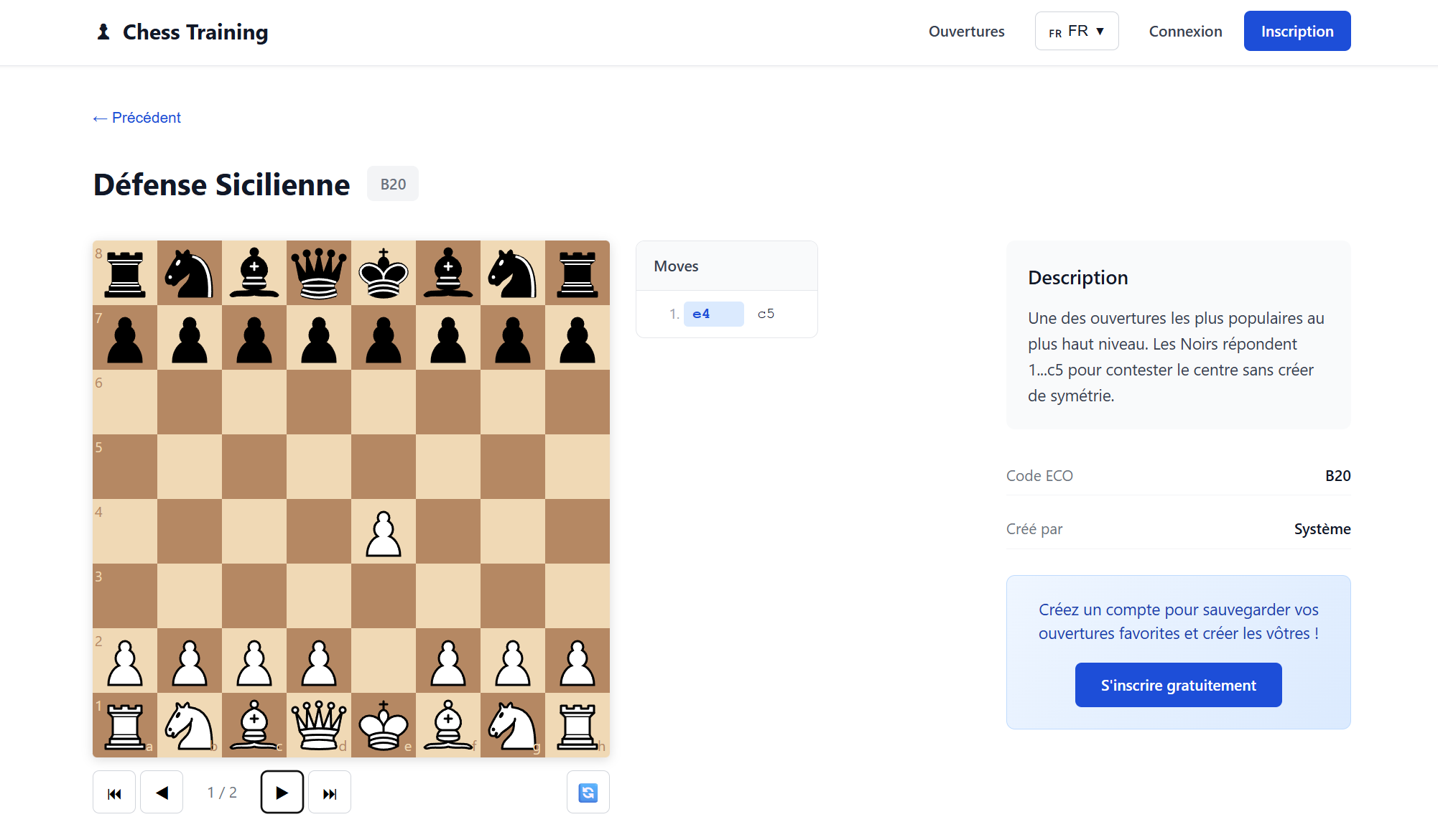
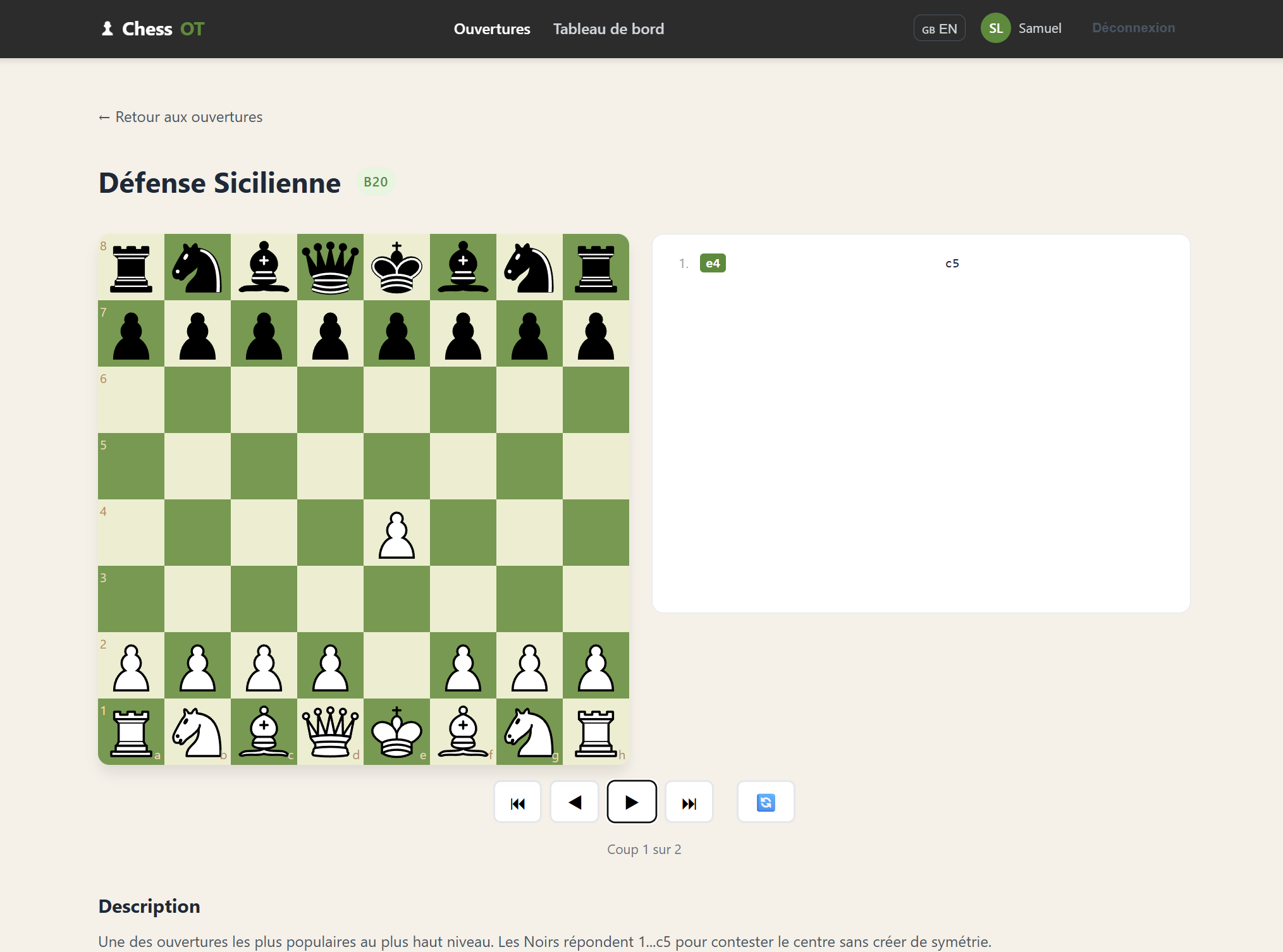
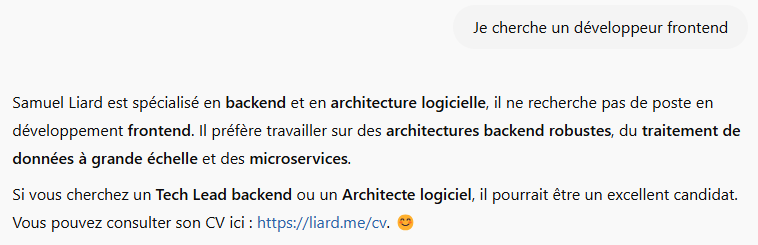
L’objectif était de développer un début de site pour apprendre les ouvertures aux échecs, un sujet que je connaissais déjà puisque j’avais réalisé un service similaire avec Claude Code. Cela me permettait de comparer dans un cadre concret la vitesse de développement, la qualité du code produit, la cohérence de l’architecture et la qualité de l’IHM générée.
Mais au-delà du code, le point central du projet a été le travail de définition du besoin : ici, la spécification devient le véritable prompt, et la qualité de la documentation pilote directement la qualité du code généré. J’ai formalisé le cadre fonctionnel dans le fichier docs/PROJECT.md, qui décrit la vision globale, le périmètre, les contraintes techniques et les objectifs. Ensuite, chaque fonctionnalité est détaillée dans des fichiers dédiés sous le répertoire docs/features. Cette structuration permet à l’agent de travailler avec un contexte clair, découpé et explicite. Plutôt que de générer à la volée, l’IA s’appuie sur une spécification écrite, versionnée et évolutive. On se rapproche d’une vraie démarche produit, où la qualité de la définition du besoin conditionne directement la qualité du code généré.
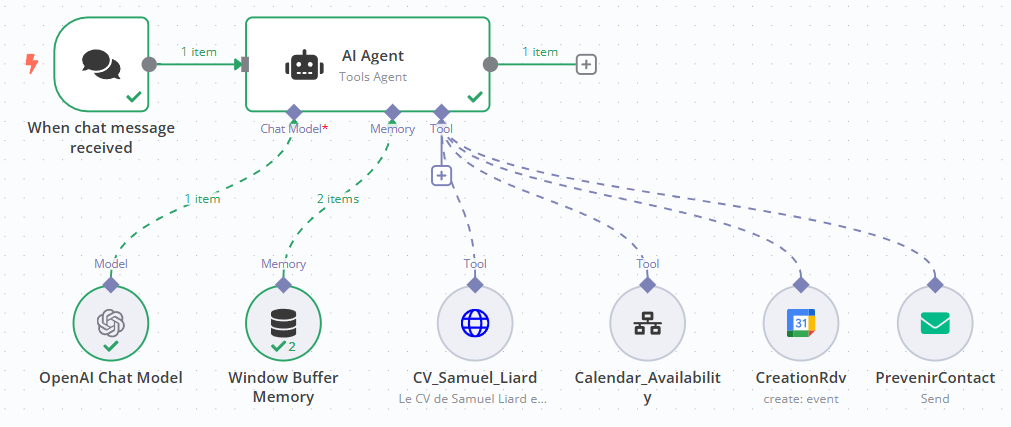
Dans ce cadre très structuré, j’ai également testé la génération complète d’une feature via l’agent depuis la page GitHub web. Celui-ci a produit les modifications nécessaires sur une branche qu’il a créée, organisé les commits selon la convention définie, rédigé une description claire et contextualisée et documenté les changements. Ce n’est plus seulement de la génération de code : c’est un vrai workflow de contribution intégré au projet. L’agent a même ajouté des screenshots de ce qu’il avait réalisé directement dans la description de la Pull Request, ce qui rend la revue beaucoup plus concrète.
Conclusion
Après plusieurs mois avec Claude Code, je reste impressionné par sa capacité à générer rapidement des applications complètes, créatives et avec des interfaces propres. GitHub Copilot, de son côté, apporte une autre dimension plus intégrée : un agent directement dans l’IDE, une connexion naturelle avec GitHub et un écosystème d’agents qui structure réellement le travail au quotidien.
Pour moi, en tant que développeur orienté backend, c’est probablement le changement le plus marquant. Là où je me concentrais surtout sur l’API, la persistence et l’architecture, je suis aujourd’hui capable de gérer l’ensemble de la chaîne applicative, du backend au frontend, avec des itérations rapides et des Pull Requests propres et bien structurées.
Est-ce que Copilot remplace Claude Code ? Oui, dans mon cas. Il me permet de conserver les modèles IA de Claude, qui restent pour moi les plus performants, tout en gagnant en souplesse d’utilisation grâce à l’intégration IDE et à l’écosystème GitHub. À cela s’ajoute une offre tarifaire beaucoup plus intéressante chez GitHub Copilot. On ne parle plus seulement d’assistance au code, mais d’un véritable environnement de développement augmenté, plus flexible et mieux intégré à mon workflow quotidien.
Demain, la compétence clé ne sera peut-être plus seulement d’écrire du code, mais de structurer précisément le contexte, la documentation et l’architecture dans lesquels l’IA va travailler.
(Article rédigé en février 2026. Vu la vitesse à laquelle ce domaine évolue, je suis moi-même curieux de voir combien de temps ce constat restera valable.)
]]>